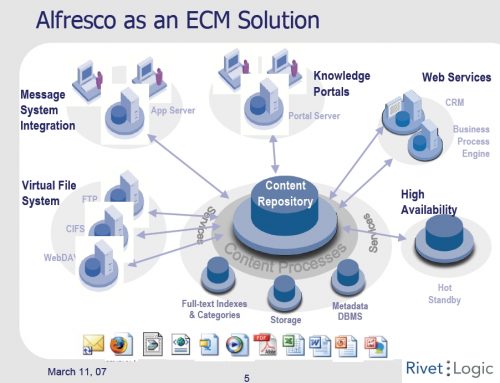
z39.50의 업그레이드 – SRU 프로토콜
SRU 개요
SRU는 ‘Search & Retrieval via URL’의 약어로서 미의회도서관(LC)에서 제정한 국제표준 프로토콜입니다. 이 프로토콜은 우리가 흔히 도서관의 소장목록을 검색하기 위해 사용해왔던 전통적인 z39.50의 발전적인 형태라고 할수 있는데요, 네트워크 상에서 데이터베이스를 탐색하고 그 결과를 보내기 위해 URL 을 사용하는 탐색 및 검색 프로토콜입니다. 여기서 중요한 것이 ‘URL’을 사용한다는 점인데요, 쉽게 설명드리면 익스플로러 같은 웹 브라우저 주소창에 URL 형식의 리퀘스트를 입력하면 SRU 서버를 거쳐 정해진 양식의 응답이 오게 되는 것입니다.
저희 회사가 지난해 한국과학기술원(KAIST)에서 수행한바 있는 ‘개인화 전자도서관서비스'(http://ilibrary.kaist.ac.kr) 프로젝트에 이 프로토콜이 적용되었는데요, KAIST 전자도서관의 소장목록에서 검색결과 데이터를 불러오기 위해 이 프로토콜을 사용한 것입니다. 이 프로젝트에 SRU 프로토콜이 적용됨으로서 KAIST의 소장목록 데이터를 불러오기 위해 별도의 API를 개발해야 하는 수고를 덜게된 것이지요. SRU 프로토콜이 실제 적용된 예는 아래에서 자세히 설명드리겠습니다.
만약 이 글을 읽고 계시는 여러분들의 전자도서관 시스템에 이 SRU 프로토콜이 적용되어 있다면, 단순히 URL만을 이용하여 외부에서 여러분 기관의 소장목록정보를 가져갈 수가 있게 되는 것입니다. 역으로 여러분들은 SRU 프로토콜이 적용되어 있는 세계의 어느 도서관(LC같은)에서도 소장목록 정보를 URL 만으로 가져올 수가 있게 됩니다. 즉, 예전처럼 소장목록 데이터를 LAS 시스템에서 반출하고 또다시 반입하는 등의 복잡하고 어떻게 보면 성가신 과정들을 겪지 않아도 되는 것이지요.
※ z39.50 : 네트워크를 통한 데이터베이스 탐색과 레코드 검색을 위한, 클라이언트와 서버 간의 메시지 교환 형식과 절차를 규정한 미국국가 표준이자 국제표준
SRU 특징
SRU 프로토콜은 아래의 4가지 특징을 지니고 있습니다.
첫째, 앞서 설명드린바와 같이 SRU 프로토콜은 도서관의 소장목록을 검색하기 위해 사용해왔던 전통적인 z39.50 프로토콜의 업그레이드 버전이라 할 수 있습니다. z39.50 프로토콜의 개념은 대부분 유지하면서 웹기반, 즉 URL 기술을 추가한 것이지요.
둘째, REST 방식을 사용합니다. SRU 프로토콜과 유사한 SRW(Search & Retrieval via WebService) 프로토콜이 SOAP(Simple Object Access Protocol) 방식을 사용하는데 비해 SRU 프로토콜은 REST(Representational State Transfer) 방식을 사용합니다.
셋째, SRU 프로토콜은 유동적(Flexible)인 성격을 지니고 있습니다. z39.50 프로토콜처럼 Session 중심의 고정적(Stateful) 성격을 지니지 않으며, 웹기반(URL)이므로 매우 유동적(Flexible)이라 할 수 있습니다.
넷째, XML을 사용합니다. SRU 프로토콜은 레코드 구문으로 XML 언어를 사용합니다.
주요기능 (Operation)
SRU 프로토콜은 크게 3가지 기능(Operation)으로 이루어져 있는데, 각각의 기능에 대한 설명은 아래와 같습니다.
첫째, SearchRetrieve Operation 입니다. 이 기능은 SRU/SRW 프로토콜의 핵심적인 기능으로, 레코드 검색을 위하여 원격지 서버로 질의문/파라미터를 전달하는 역할을 합니다.
둘째, Scan Operation 입니다. SearchRetrieve 기능처럼 원하는 레코드 전체를 요청하는 것이 아니라 원하는 색인에 해당하는 정렬 리스트를 요청하고 응답받는 기능입니다. 다시말해서 SearchRetrieve 기능이 전체 레코드 내에서 특정 용어로 탐색 가능하게끔 하는 오퍼레이션이라면, Scan 오퍼레이션은 색인된 리스트 내에서 클라이언트가 가능한 용어들의 범위를 요청하게끔 합니다. 이를 통하면 클라이언트가 그 값들의 정렬된 리스트를 보이게끔 할 수 있습니다.
셋째, Explain Operation 입니다. 이 기능은 서버와 관련된 정보를 확인할 수 있는 기능으로, 클라이언트가 이용자에게 적절한 인터페이스를 제공하기 위해 스스로 세팅할 수 있도록 해주는 역할을 합니다.
Request & Response
SRU 프로토콜은 ‘Client – Server Model’ 을 기본으로 합니다. 즉, 아래 그림과 같이 Client에서 SRU Protocol을 이용한 질의어를 Server로 전송하면 Server에서는 Client 요청에 따른 메타데이터를 표준 XML형식으로 변환하여 다시 Client에 전송하는 방식입니다.

위에서 살펴본 SRU 프로토콜의 3가지 기능의 Request/Response 파라미터(parameter)는 다음과 같습니다. 노란색으로 강조된 부분은 반드시 필요한 파라미터들을 의미합니다.
- Request Parameters

- Response Parameters

또한 SRU Server로 Request를 보낼때는 아래와 같이 정해진 구문(syntax)을 준수해야 합니다.
- ? : Base URL과 Request 파트를 구분
- & : 각 파라미터를 구분
- = : 파라미터와 그 값을 연결
- ?,&,= 전후에 공백이 들어가면 안됨
- 각 파라미터의 순서는 관계 없음
- Syntax를 준수하여 작성된 Request URL 의 예 (※URL을 클릭하면 실제 Respose된 결과를 보실수 있습니다)
http://kaede.nier.go.jp:80/epi?version=1.1&operation=searchRetrieve&query=english
KAIST 전자도서관에 적용된 사례
기관의 전자도서관 시스템에 SRU 프로토콜을 적용하기 위해서는 기관 고유의 ‘Base URL’이 필요합니다. KAIST 전자도서관 시스템에 부여된 Base URL은 http://library.kaist.ac.kr/openAPI/KAISTSearch.php 입니다. 이제 이 Base URL을 이용하여 실제 Request를 보내보도록 하겠습니다.
- KAIST 전자도서관 소장목록에서 서명(Title)에 ‘harry’가 들어간 자료를 검색할 경우
- KAIST 전자도서관 소장목록에서 서명(Title)에 ‘중국견문록’이 들어간 자료를 검색할 경우
- http://library.kaist.ac.kr/openAPI/KAISTSearch.php?type=b&query=title=%EC%A4%91%EA%B5%AD%EA%B2%AC%EB%AC%B8%EB%A1%9D&startRecord=1&maximumRecords=1
- 이 URL을 클릭하면 실제 KAIST 전자도서관 소장목록에서 검색되어진 결과를 보실수 있습니다