학술정보 추천서비스
추천서비스 개요
추천서비스는 이용자에게 새로운 정보를 추천해주는 서비스로써 뉴스, 영화, 도서, 음악, 학술정보 등의 추천에 널리 응용되고 있다.
최근 인터넷이 발달하면서 접할 수 있는 정보의 수와 종류가 기하급수적으로 증가하여 찾고자 하는 정보를 획득하기가 오히려 어려워졌다. 인터넷의 발달과 함께 성장한 정보검색 기술과 대용량 데이터의 처리기술 등을 기반으로 수많은 정보 중에 이용자가 선호할 만한 정보를 자동으로 추천해주는 서비스도 함께 발전하였는데, 정확한 분석 및 서비스를 위하여 다양한 추천 알고리즘이 발명되어왔다.
본 글에서는 추천서비스의 대표적인 두 분야인 로그 기반의 추천서비스(CF)와 콘텐트 기반의 추천서비스(CBF)를 소개하려고 한다.
콘텐트 기반 추천서비스
콘텐트 기반의 추천서비스는 CBF(Content-Based Filtering)라고도 하는데 아이템의 콘텐트를 직접 분석하여 아이템과 아이템, 아이템과 이용자 선호도간의 유사성을 분석하여, 이를 바탕으로 새로운 아이템을 추천해주는 서비스이다. 아이템 자체의 메타 데이터를 통해서 내용을 분석할 수 있기 때문에 주로 텍스트 기반의 뉴스나 인터넷 기사, 도서, 학술정보, 영화, 음악 등에 대한 추천 시스템에서 주로 사용된다.
간단하게는 이용자 선호도에 관계없이, 특정 아이템에 대한 유사 아이템을 제공하는 서비스가 가능한데, 음악 사이트에서 제공하는 유사 앨범이나 유사 아티스트 리스트 또는 도서관에서 제공하는 주제별 신간정보 서비스가 이에 해당한다.
이용자의 선호도에 따른 추천정보를 제공하기 위해서는 특정 이용자에 특화된 프로파일이 필요하다. 즉, 이용자의 프로파일을 분석한 선호도를 각 아이템의 내용과 비교하여 이용자의 선호도가 높을 것으로 예상되는 아이템을 추천하는 것으로 이용자별 키워드 기반의 Alert 서비스 등이 이에 해당한다.
CBF의 단점
- 다룰 수 있는 콘텐트는 대부분 텍스트로서 그 범위가 좁다.
- 추천 정보가 하나의 분야나 경향에 집중되기 싶다.
- 이용자에 대한 추천은 프로파일이 생성되어야만 추천할 수 있는데, 로그 사용 없이 이용자의 프로파일 생성이 어렵다.
[국내 음악 사이트에서 사용하고 있는 CBF의 예]
로그 기반 추천서비스(Collaborative Filtering)
로그 기반 추천서비스는 CF(Collaborative Filtering)라고도 하는데 로그정보를 기반으로 하여 특정 이용자의 성향과 비슷한 다른 이용자의 성향을 통합/분석하여 새로운 아이템에 대한 선호도를 예측하는 시스템이다. 이것은 사람들의 성향은 무작위로 분포된 것이 아니라 일정한 트렌드와 패턴이 있다는 가정에서 출발하는 것이다.
인터넷 서점에서 제공하는 구매이력 로그를 이용한 추천도서 정보나 별점을 부여하는 영화에 대한 평가 로그를 이용한 영화추천 서비스 등이 이에 해당한다.
CF는 CBF가 갖고 있는 한계점의 일부를 해결해 주는데, 자동으로 분석이 어려웠던 영상, 음향, 아이디어, 감정 등의 속성이 이용자의 평점으로 평가되기 때문에, CBF에서 다루지 못했던 아이템들에 대한 추천이 가능하다. 또한 이용자의 취향이나 아이템의 질에 기반을 둔 추천을 가능하게 한다. 그리고 무엇보다, 다른 이용자의 경험을 바탕으로 하기 때문에 이용자가 기존에 선호해왔던 정보와는 다르지만, 다른 이용자가 높이 평가할 수 있는 정보에 대한 추천도 가능하다.
CF의 단점
- 시스템에 새로운 정보가 추가되었을 때, 이에 대한 이용자 평점이 쌓이기 전에는 이 정보를 추천할 방법이 없다.
- 이용자의 수가 적으면 공통된 정보에 대해 평점을 내린 이용자 집단이 작기 때문에 Nearest-Neighborhood를 찾기 어렵고, 결과적으로 시스템의 성능이 저하된다.
- 독특한 취향을 가진 이용자의 경우, 유사 취향의 이용자가 드물다면 이 이용자에게 좋은 추천 서비스를 해주는 것을 기대하기 어렵다.

[Amazon에서 실제 사용하고 있는 CF의 예]
콘텐트 기반의 추천서비스 – R2GotIt
개요
- 기존에 서비스 되고 있는 Alerts서비스라 불리는 SDI(Selective Dissemination of Information) 서비스 및 RSS(Really Simple Syndication) 는 두 가지 측면에서 한계를 가진다. 첫째, 연구자가 먼저 자신의 관심 키워드를 등록한 경우에 대해서만 서비스가 이루어진다. 둘째, 연구자의 변화하는 관심 분야를 시스템이 능동적으로 파악할 수가 없다는 점이다.
- 이러한 한계를 뛰어넘기 위해서는 연구자의 관심 사항을 파악하기 위한 다른 방안이 필요한데, R2GotIt은 연구자의 관심 사항을 파악하기 위해 보고서, 연구논문 및 특허와 같은 연구 성과와 대출, 원문신청 등의 자료수집 데이터로부터 연구자별 프로파일을 생성하도록 한다.
- 이렇게 이용자의 연구활동에 대한 분석을 통해 생선된 이용자별 프로파일과 추천 정보의 유사도를 계산하여 연구자별 맞춤형 최신정보를 제공한다.
특징
- TF-IDF (Term Frequency – Inverse Document Frequency) 알고리즘을 기본으로 학술정보 추천에 적합하도록 개선한 알고리즘 적용
- 내부의 최신정보 및 외부의 해외논문, 국내논문, 특허정보 등 다양한 정보원으로부터 서비스 대상을 수집/제공할 수 있는 아키텍쳐 구성
- 설정파일 변경을 통한 운영환경 설정
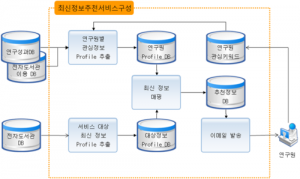
[GotIt시스템 구성도]
적용사이트
- 한국과학기술연구원(KIST)
- 카이스트(KAIST)
- 국방과학연구소(ADD)
- 한국원자력연구원(KAERI)

[KIST에서 발송된 서비스 메시지 사례]
로그 기반의 추천서비스 – R2Cat+
개요
- CAT+는 Cataloguing Plus의 줄임말로써 도서관에서 제공해오던 전통적인 목록서비스(Cataloguing Service)에 외부정보를 추가하여 서비스 품질을 향상시키겠다는 의미
- 한정된 정보로 서비스되는 도서관 웹서비스의 상세보기 화면을 이용자 로그를 활용하여 적합한 관련자료를 추천해 주며, 국내외 단행본 도서 정보를 자관의 정보서비스와 통합해주는 솔루션
- CAT+의 추천서비스 및 외부 인터넷 서점 검색 통합을 통해 도서관 단행본 서비스의 수준으로 향상 가능.
특징
- 전자도서관에서 이용자가 원하는 정보를 검색하는 과정에서 관련자료를 추천해줌으로써 이용자의 정보검색 효율을 높일 수 있는 선도적인 서비스
- 다수 전자도서관의 참여와 공유를 통해 더욱 수준 높은 서비스가 가능
- 상세보기 로그 정보 활용 – 동적인 서비스 가능
- 국내외 인터넷 서점검색을 통한 망라적인 단행본 검색 가능
- 자관의 소장도서검색과 연계, 희망도서신청 연계, 직접구매 링크 등의 기능 제공

[R2Cat+서비스 구성도]
적용사이트
- 카이스트(KAIST)
- 한국생명공학연구원(KRIBB)
- 울산과학기술대학교(UNIST)
- 경기개발연구원(GRI)
- 한국해양연구원(KORDI)
- 한국노동연구원(KLI)
- 서울시정개발연구원(SDI)

[서비스 사례 – KAIST 단행본 상세화면 사례]
추천 알고리즘
- Repeat Buying Theory의 LSD Model

[Repeat Buying Theory의 LSD Model 알고리즘 관련 이미지 1]

[Repeat Buying Theory의 LSD Model 알고리즘 관련 이미지 2]

[Repeat Buying Theory의 LSD Model 알고리즘 관련 이미지 3]